
网络出问题,等用户投诉才知道?信锐AI模拟感知:变"救火"为"防火"
最让IT头疼的瞬间:老板打电话说"会议室视频卡了",你一脸懵——没收到任何告警啊?
跑过去一看,确实卡了。但问题是——为什么卡了没人知道?
传统网络运维有个根深蒂固的痛点:被动响应。
网络设备正常、链路没有告警、没有宕机——你看着监控大屏一切绿,但用户的真实体验已经"黄了"很久了。等用户投诉才知道问题,这就是典型的"救火式运维"。
有没有办法在用户发现之前,提前知道网络要出问题?
信锐给出的答案是:AI模拟感知(业务质量先知)——让网络自己"假装"成用户,7×24小时持续探测,在用户投诉之前主动发现隐患。
一、传统运维的"盲区":设备好好的,为什么体验差?
先看一个典型场景:
某天上午10:00,办公室网络监控面板显示所有设备在线、所有端口正常、CPU负载低于50%。
上午10:15,财务总监反馈"ERP系统登录不上"。
你跑去查:认证服务器响应超时,但监控系统没有针对服务器的探测——所以没有任何告警。
排查耗时:45分钟。影响业务:全财务部无法报账。
问题出在哪?
传统的网络监控机制是"被动告警"——看的是设备"活着还是死了"(SNMP up/down、端口状态、CPU负载),但从来没问过"用户的体验好不好"。
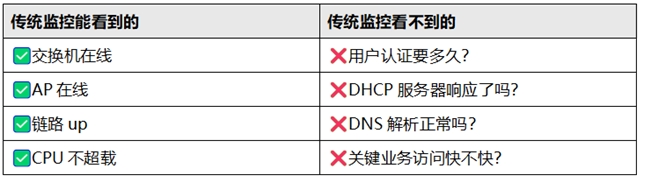
没告警 ≠ 没问题。 这是传统运维最大的盲区。
二、信锐AI模拟感知:让网络"扮成用户"去体验
信锐的解法很简单直接:如果不能直接知道用户的体验,那就让网络自己变成"用户",主动去探测。
这套机制分为两个层面——无线侧和有线侧,双管齐下。
无线侧:AP内置独立AI射频芯片,7×24小时模拟终端
每台信锐智感AP配备了两颗芯片:
业务芯片:处理用户正常的无线接入和数据转发
-
智感AI芯片:独立的AI射频芯片,专职"模拟终端",不占用业务资源
这颗AI芯片干的事:
-
模拟终端接入:假装成一个普通用户,发起Wi-Fi连接流程
-
模拟认证:走完完整的认证流程(802.1X、Portal等)
-
模拟上网:访问网络中的关键服务器
-
全链路监测:接入→认证→DHCP→DNS→业务访问,每个阶段的状态都记录
AP内置独立AI射频芯片,7×24小时模拟终端,全程监测接入、认证、上网各阶段状态。
因为是专用的独立AI芯片,所以对正常用户的业务没有任何影响——模拟检测和真实业务互不干扰。
有线侧:交换机变身"AI终端",主动探测关键业务
无线侧模拟的是"终端用户",有线侧模拟的是"业务访问"。
信锐智感交换机可以化身AI终端,主动对关键业务服务器发起访问探测:
交换机模拟AI终端,主动对关键业务服务器发起访问探测(最大96次/天/业务)。
这意味着:
交换机会定期"假装"访问ERP服务器,检查是否正常响应
-
交换机会测试DHCP服务器的地址分配是否正常
-
交换机会检测认证服务器的可达性和响应时间
每项业务每天最多探测96次——大约每15分钟一次,基本能做到分钟级的感知粒度。
三、从"救火"到"防火":效果对比
四、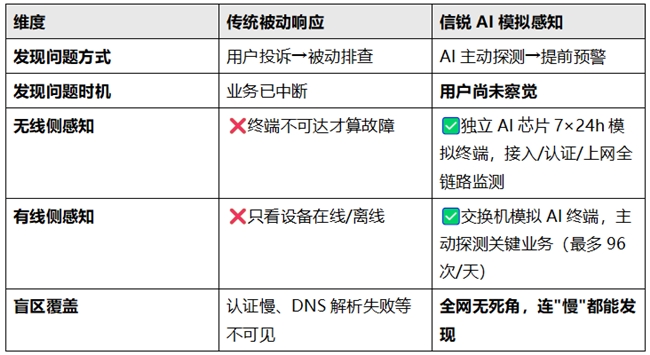
在用户投诉前,提前发现网络盲点、认证失败、业务响应慢等隐患,变"救火"为"防火"。
四、这不是单个功能——这是"全网智能2.0"的感知层
AI模拟感知并不是一个孤立的功能。它是信锐"全网智能2.0"(A5i能力架构)中的i-Sense(智能感知) 层。

i-Sense(感知):本文讲的AI模拟感知,采集真实体验数据
-
i-Think(分析):1400+异常识别模型,分析数据找根因
-
i-Choose(决策):给出处置建议或自动决策
-
i-Do(执行):自动执行网优、故障自愈
-
i-Show(呈现):把结果用可视化方式呈现给IT人员
再加上小信GPT的自然语言交互,IT人员在控制器上直接问"今天网络有问题吗?"就能得到答案。
全网智能2.0,A5i能力架构。i-Sense智能感知:全方位采集数据,接入层智能化,主动感知网络状态,独立AI芯片,业务运转不受影响。
参考来源:2025年无线联接价值主打V0.91-0120.pptx
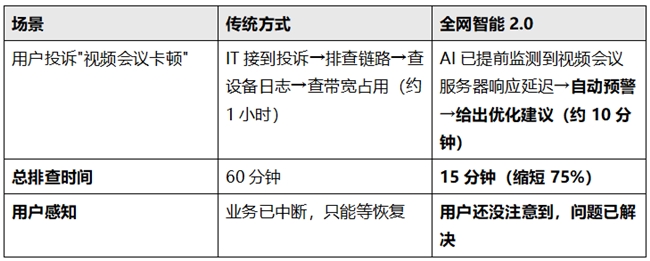
五、实际效果:排查时间缩短70%+
信锐全网智能2.0在实际部署中的效果数据:
基于"全网智能2.0"+ 小信GPT,快速定位问题,排查时间缩短70%+,故障时长缩短80%。
参考来源:2025年无线联接价值主打V0.91-0120.pptx
一个例子说明这个数字的价值:
写在最后
"没告警不等于没问题"——这个认知差,是很多企业网络运维"被动挨打"的根本原因。
信锐AI模拟感知的底层逻辑很简单:把判断的主动权从"用户投诉"转移到"网络自检"。不需要等用户说"我连不上了",网络自己每天都在模拟用户、探测业务——用户体验好不好,网络自己最清楚。
变"救火"为"防火",这才是智能运维该有的样子。
如果你的IT团队还在每天"救火"——收到的第一个告警永远是老板的消息——该让网络学会自己先走一步了。
参考来源:
- 2025年无线联接价值主打V0.91-0120.pptx
- 信锐交换机价值主打PPT【20251113】.pptx
- 相关阅读:
-
零中断、零管理、高安全——企业级网络设备的"三大体验底线"2026-06-09抖音生活服务“有花就开水友赛”4月13日落地西双版纳,泼天祝福等你来接2026-04-12MLILY梦百合获艾媒咨询“中国智能床第一品牌”等三项市场地位确认2025-01-14自建站突破900座,第三方桩接入超70万,极氪补能网络持续进化2024-04-02梦百合捐赠枕头床垫等应急物资,驰援青海震区2023-12-27
- 猜你喜欢:
-
光大云缴费2022年缴费金额已超千亿元2022-03-21姜荟·惜源品牌首席执行官—婷姐,携手惜源共创私护大健康神话2019-07-17政企同心谋发展,菲诺总裁张凯建言献策,助力嘉兴特色产业高质量发展2025-12-04感恩夏桂英中医7天康复疗法让偏瘫患者重新站起来,生活恢复自理2022-10-20MLILY梦百合发布青少年0压睡眠新品及解决方案2024-04-23珠海长隆旅游美食地图上线引关注,多重场景构建立体珠海文旅体验2024-08-12
